SQL: The Language of Databases
Complete Guide To SQL

SQL, short for Structured Query Language, is the language of databases. It allows us to communicate with and manipulate vast amounts of data stored in various database management systems. Whether you are an aspiring data analyst, a software developer, or simply curious about databases, understanding SQL is a valuable skill that opens up a world of possibilities. In this article, we will embark on a journey to demystify SQL and explore its significance in the realm of data.
Content:
1. What is SQL
2. Why do we need SQL
3. Examples of Using SQL
4. SQL vs No SQL
5. Databases and Where they Should Live
6. SQL Tutorial
The Essence of SQL:
SQL is the universal language for managing relational databases. It provides a standardized way to interact with data stored in tables, regardless of the underlying database system. Whether you're using SQL Server, PostgreSQL, MySQL, or other popular database systems, the core principles of SQL remain consistent.
Data Storage and Tables:
At the heart of SQL lies the concept of data storage through tables. Tables are structured collections of data, organized into rows and columns. Each row represents a specific record, while columns define the attributes or fields of that record. To illustrate, let's consider a hypothetical table documenting online activities:

In this example, each row represents a specific online activity, while the columns capture different attributes such as date and time, platform, action, and time spent in seconds.
Data Queries
Unleashing Insights:
One of the primary reasons we use SQL is to extract valuable insights from our data. Through queries, we can ask specific questions and retrieve relevant information. Consider the following scenario: you want to determine how much time you spent online in September. Using SQL, you can simply ask the database:
Q: "Hey, data. Can you tell me how much time I spent online in September?"
The database then responds:
A: "You spent 1.2 million seconds in September."
Building upon this, you may further inquire:
Q: "Okay, data. Can you tell me how much time I spent online in September in hours, not seconds?"
A: "You spent 360 hours online in September."
These interactions with the data are known as queries. By formulating queries in SQL, you can quickly retrieve specific information without having to manually sift through vast datasets.
The Power of Queries:
SQL queries enable us to interact with data effortlessly. By leveraging the intuitive nature of SQL, you can ask complex questions and receive accurate answers in a matter of seconds. This ability to effortlessly extract insights from large datasets makes SQL an invaluable tool for data analysts, researchers, and decision-makers.
Conclusion:
SQL is a powerful language that allows us to communicate with databases and gain valuable insights from our data. By understanding SQL's fundamentals, you can unlock the potential to extract, manipulate, and analyze large datasets efficiently.
Other Uses of SQL
Structured Query Language (SQL) is a powerful tool that goes beyond its well-known role of querying data from databases. While data retrieval through queries, known as Data Query Language (DQL), is the most common use case, SQL offers other functionalities that are equally important and valuable. In this article, we will dive deep into the various uses of SQL and explore its broader capabilities.
1) Data Query Language (DQL):
DQL, the fundamental use of SQL, involves fetching data from a database based on specific conditions. Using the SELECT command, you can retrieve data that meets your criteria. For instance, if you want to determine the total time spent online in September, the SQL query would look like this:

2) Data Definition Language (DDL):
SQL also enables you to perform actions on the database structure or schema. This functionality is known as Data Definition Language (DDL). It allows you to create, alter, or delete tables, databases, and columns. Let's explore a few common DDL commands:
a. CREATE: This command is used to create a new table. For example:


b. DROP: If you need to remove tables or databases, the DROP command comes in handy. For instance:

c. ALTER: The ALTER command allows you to modify the structure of a table. Suppose you want to add a new column of type varchar. Here's how you can do it:

d. TRUNCATE: If you wish to empty a table and start afresh, you can use the TRUNCATE command:

3) Data Manipulation Language (DML):
Apart from querying and modifying the database structure, SQL provides capabilities for data manipulation. This is referred to as Data Manipulation Language (DML). DML commands allow you to insert, update, and delete records in a table.
a. INSERT: To add new records or rows, you can use the INSERT INTO statement.
For example:


b. UPDATE: If you need to modify existing data, the UPDATE statement is useful. Let's say you want to change the owner of DeviceID 4 to Jon:


c. DELETE: When you want to remove specific rows from a table, you can use the DELETE command. For instance, if you only want to display your devices and exclude Jon's devices:

4) Other SQL Commands:
Beyond DQL, DDL, and DML, SQL offers additional commands that cater to specific needs:
a. Data Control Language (DCL): These commands involve granting or revoking permissions to users, allowing fine-grained control over data access.
b. Transaction Control Language (TCL): TCL commands manage transactions within the database. They include COMMIT to save transactions and ROLLBACK to undo uncommitted changes.
Conclusion:
As a data analyst, it's crucial to realize that SQL's potential extends beyond simple data querying. By leveraging DQL, DDL, and DML commands, you can retrieve, define, alter, and manipulate data effectively.
Why is SQL Beneficial
SQL is High Performance:
One of the key strengths of SQL is its exceptional performance, even under heavy workloads and high usage. SQL has been proven to work seamlessly with complex databases, handling large volumes of data and numerous transactions simultaneously. Its efficiency ensures that data retrieval and manipulation occur swiftly, providing fast and reliable results.
SQL is Accessible:
SQL is widely accessible, as it is compatible with most relational database management systems. Whether you are using Microsoft SQL Server, Oracle Database, MySQL, Azure, BigQuery, Amazon Redshift, or Snowflake, SQL support is readily available. Furthermore, SQL extends beyond traditional database management and allows for the creation of application extensions for procedural programming. This versatility makes SQL a preferred choice for developers and data professionals.
SQL is Highly Scalable:
Scalability is a critical factor in the ever-expanding world of data. SQL excels in this aspect, offering seamless scalability options. Creating new tables or transferring existing tables to new databases is incredibly easy with SQL. Tables can be effortlessly dropped or created as per your needs, allowing for smooth database expansion and adaptation to evolving data requirements.
SQL has Great Security Features:
Data security is of paramount importance in today's digital landscape. SQL provides robust security features that are easy to manage. With SQL, permissions can be assigned and verified with simplicity, ensuring that only authorized individuals have access to sensitive data. This level of control enhances data protection and safeguards against unauthorized access or data breaches.
Requires Little Coding Knowledge:
One of the remarkable advantages of SQL is its simplicity and ease of use, particularly for data retrieval and analysis. Learning SQL requires only a basic understanding of select, insert, update, and into functions, along with their syntax. This minimal coding knowledge empowers users to perform complex queries, generate insightful reports, and extract valuable information from databases without extensive programming expertise.
Conclusion:
SQL is a game-changer in the world of data management. Its high performance, accessibility, scalability, security features, and simplicity make it an indispensable tool for data professionals and businesses alike. By harnessing the power of SQL, users can unlock the full potential of their data, enabling efficient data manipulation, insightful analysis, and informed decision-making. Whether you're working with small datasets or handling massive volumes of information, SQL proves to be an asset that revolutionizes data management practices. Embrace the benefits of SQL and take your data management to new heights.
Relational Databases
Relational databases play a fundamental role in the world of data management, and SQL serves as the language that allows us to interact with these databases. In this article, we will delve into the concept of relational databases and explore how tables, keys, and relationships form the backbone of these powerful systems.
Tables and Relationships:
At its core, a relational database management system (RDMS) is a database that stores data in the form of tables. Each table comprises rows (also known as records) and columns (also known as attributes or fields). These tables can be linked or related to one another, forming relationships that provide valuable insights and enable efficient data retrieval.
Let's examine a simple example to illustrate the concept of relationships:
1) Customer Table:

2) Order Table:
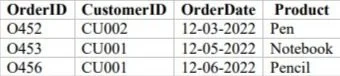
In this scenario, the Customer Table and the Order Table are related through a key known as the CustomerID. The CustomerID serves as the primary key in the Customer Table, representing a unique identifier for each customer. This primary key can then be added to another table, such as the Order Table, where it becomes a foreign key.
Primary and Foreign Keys:
The primary key is a unique identifier within a table, ensuring that each row represents a distinct record. In our example, the CustomerID column serves as the primary key in the Customer Table since each CustomerID corresponds to a unique customer.
On the other hand, the Order Table has its own primary key, the OrderID, which uniquely identifies each order. However, the CustomerID column in the Order Table is a foreign key. It establishes a link between the Order Table and the Customer Table, allowing multiple orders to be associated with a single customer.
Building Relationships:
The primary and foreign key relationship forms the foundation of relational databases. It enables data integrity and consistency by ensuring that related data is properly linked and maintained. Through these relationships, SQL queries can retrieve data from multiple tables, combining information to generate valuable insights and meaningful reports.
Conclusion:
Relational databases and the SQL language provide a robust framework for organizing and manipulating data. By understanding the concept of tables, keys, and relationships, you can harness the full potential of these systems. The ability to establish connections between tables through primary and foreign keys allows for efficient data retrieval, analysis, and reporting. Relational databases, supported by SQL, continue to be a cornerstone of data management, empowering businesses, and data professionals to unlock valuable insights from their vast datasets.
Now you get something like NoSQL
In the realm of data management, traditional relational databases have long been the go-to solution. However, as technology advances and the need for more flexible and scalable data storage arises, NoSQL databases have gained popularity. In this article, we will delve into the world of NoSQL databases, exploring their unique characteristics, benefits, and their place alongside traditional SQL databases.
NoSQL: A Non-Relational Approach:
NoSQL, short for "Not only SQL," represents a non-relational data management system that diverges from the fixed schema structure of traditional SQL databases. Unlike SQL databases, NoSQL databases do not rely on tabular structures with predefined columns and rows. Instead, they store data in flexible formats like JSON (JavaScript Object Notation).
Example of a JSON format:

To visualize the difference, consider the following example:
1) SQL Representation:

2) NoSQL Representation:


Benefits of NoSQL
Flexibility and Scalability:
The key benefit of NoSQL databases lies in their flexibility. Without a rigid schema, NoSQL databases can accommodate a variety of data formats and structures. This makes them well-suited for scenarios where data relationships are not clearly defined or when dealing with unstructured data. The JSON representation allows for easy manipulation and dynamic updates, enabling developers to adapt to changing requirements seamlessly.
Moreover, NoSQL databases excel in handling vast volumes of data. Their distributed architecture enables horizontal scalability, meaning they can effortlessly handle increasing workloads by distributing data across multiple servers. This scalability is particularly beneficial in applications that require high-performance processing, such as real-time analytics, social media platforms, and e-commerce websites.
Prominent NoSQL Databases:
MongoDB and DynamoDB are two well-known NoSQL databases that have gained significant traction in the industry. MongoDB, a document-oriented database, stores data in JSON-like documents and offers powerful querying and indexing capabilities. DynamoDB, a key-value store database developed by Amazon Web Services, provides fast and predictable performance for applications with massive workloads.
SQL vs. NoSQL: Finding the Right Fit:
While SQL databases continue to dominate the data analytics landscape, NoSQL databases have carved out their niche. SQL databases excel in scenarios where data relationships are well-defined and structured, making them ideal for transactional systems and complex reporting. On the other hand, NoSQL databases shine when dealing with unstructured or rapidly changing data and when horizontal scalability is crucial.
Conclusion:
NoSQL databases offer a flexible and scalable alternative to traditional SQL databases. Their ability to handle unstructured and ever-evolving data sets, coupled with horizontal scalability, makes them indispensable for modern applications. While SQL databases still reign supreme in the data analytics realm, NoSQL databases have gained momentum and have become a valuable tool in the data management landscape. By understanding the benefits and characteristics of both SQL and NoSQL, organizations can leverage the strengths of each to meet their specific data storage and processing needs.
SQL Tutorial - Building a SQL Query
Tutorial time!
We'll cover the basics of building a SQL query using the popular W3Schools SQL editor. If you want to follow along, you can access the SQL editor at https://www.w3schools.com/sql/trysql.asp?filename=trysql_asc.
When working with SQL, you'll typically have a list of tables available in your database. These tables are often grouped into schemas, such as raw tables for data that needs cleaning and cleaned tables for reporting purposes.
To view a table, we use the SELECT statement. For example, to see all columns from the "orders" table, we can write the following query:

If you only want to see specific columns, you can list them after the SELECT keyword, separated by commas. Let's say we only want to see the "OrderID" and "OrderDate" columns:

You can add more columns as needed, following the same pattern:

To filter the results based on certain conditions, we use the WHERE statement. For example, let's find all customers located in London:

You can also use the LIKE operator to search for specific patterns in a column. For instance, if you want to find any city that contains the letters "wa," you can use the following query:

The '%' symbol represents any combination of characters. If you remove the first '%' sign, it will only match cities starting with "wa," and if you remove the last '%' sign, it will match cities ending with "wa."

Multiple conditions can be combined using logical operators such as AND and OR. For example, let's find orders with an order date greater than or equal to "1996-09-10," a shipper ID of 2, and an employee ID of 4:

Joining: The Theory
Now because this is a relational database we can join tables to get more information. Such as taking the orders table and joining customers to it. Now I’m just going to do a bit of theory to help you understand sql joins
Let’s say you have two tables. One is an order table- which shows the orders a customer has made. The other is a product table- which gives you details of the products. And you want to join these two.
Table A: Order Data

Table B: Product Data
There are four main types of joins in SQL: Inner Join, Left Join, Right Join, and Full Outer Join.
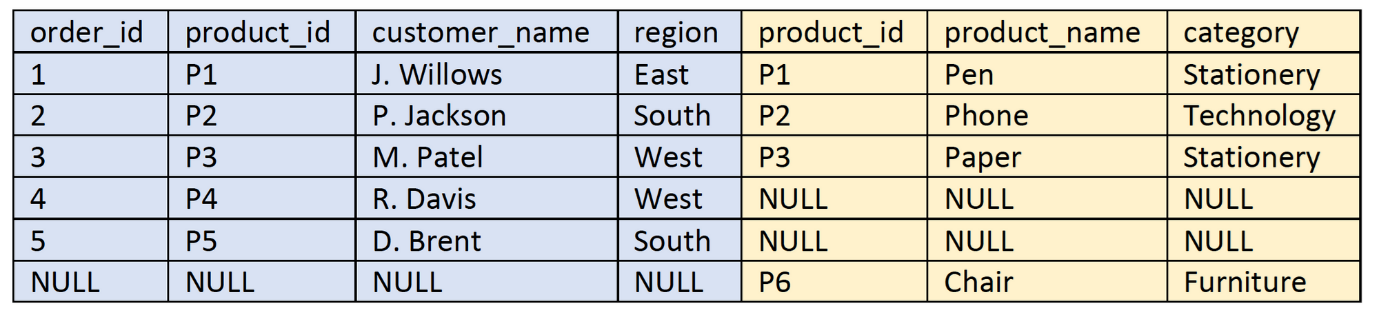
Inner Join: Returns only the records that have matching values in both tables.

Inner join produces only the set of records that match in both Table A and Table B.
So this is what you’ll see on Tableau as your final table

Because P1, P2, P3 exist in both the tables so that will only pull through.
Left Join: Returns all records from the left (primary) table and matching records from the right table.

P4 and P5 existed on the orders table but did not exist in the product table. So the final table has NULLs for product data.
P6 existed on your product table but did not exist on the orders table. The left join will bring in all rows from the left table and the matching rows from the right table. So since P6 isn’t in the orders table it won’t be brought in to your final table.
Right Join: Returns all records from the right table and matching records from the left table.


P6 existed on the product table but did not exist in the orders table. So the final table has NULLs for orders data.
P4 and P5 existed on the order table but did not exist on the product table. The right join will bring in all rows from the right table and the matching rows from the left table. So since P4 and P5 isn’t in the product table it won’t be brought in to your final table.
Full Outer Join: Returns all records when there is a match in either the left or right table.

Now full outers aren’t always available depending on the database.
Joining: The Practice
In the world of databases and data manipulation, joining tables is a critical skill that allows us to combine information from different sources. Whether you're a beginner or an experienced SQL user, understanding the various join types and their implications is essential. In this blog post, we will explore the practice of joining tables in SQL and shed light on some common scenarios you may encounter.
To begin our journey into the realm of joining tables, let's start by examining the basic syntax of a join. Consider two tables: "orders" and "customers." Our goal is to retrieve all the data from the "orders" table and combine it with the relevant customer information from the "customers" table. We can achieve this by using the following SQL query:

This simple query fetches all the records from the "orders" table. However, to enrich our data by incorporating customer details, we need to perform a join operation. When joining tables, it's crucial to determine the primary table—the table that forms the foundation of the join. In most cases, the primary table is the one with the most granular data. In this scenario, since the "orders" table contains a foreign key, "CustomerID," which can have multiple occurrences, we consider it as our primary table. As the "orderid" is unique, it becomes the primary identifier for the join.
Let's proceed with a left join to bring in all the orders and display the corresponding customer information:

By using a left join, we include all the records from the "orders" table and match them with the corresponding customers based on the "CustomerID." This means that only the customers who have placed orders will be displayed alongside their respective orders.
Remember, when constructing a join query, it is good practice to indicate the join type after the "FROM" clause. In this case, we introduce the left join, followed by the condition specifying how the two tables are linked. We start with the table we referenced first (i.e., "orders") and inform the database to join it with the "customers" table using the "CustomerID" column.
While a left join brings in all the records from the primary table, an inner join only includes exact matches. In other words, it retrieves records where the "CustomerID" appears in both the "orders" and "customers" tables:

In this example, only the orders placed by existing customers will be returned, as the inner join filters out any unmatched records.
On the other hand, a right join is rarely used because it assumes that every customer in the "customers" table has placed an order. This assumption may not hold true in most cases. Since we know that every order must be associated with a customer, using a right join in this context would be illogical.
When joining tables, it is common to implement a WHERE statement to further filter the results. However, it is crucial to specify which table a column belongs to, especially when the column appears in both joined tables. This ensures clarity and eliminates any ambiguity in the SQL query. Let's consider an example:
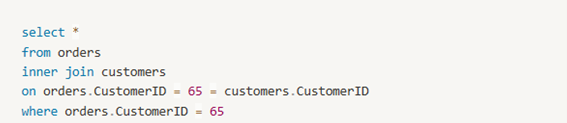
In this case, we have added a WHERE statement to retrieve orders for a specific customer with the ID 65. By explicitly referencing the table name along with the column name, we remove any potential confusion.
you can get away with something like employee id as it only show up in the orders table.

You can add multiple joins.

Aggregating
You can also perform calculations. An aggregate function in SQL performs a calculation on multiple values and returns a single value. You can also do count, average, min, max

You can also do avg

min/max

Count
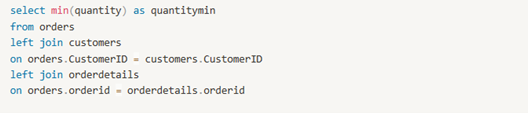
Count distinct.

Group by
If you want the quantity per customer

or quantity per customer and employee

Order By
Using order by will order your table based on a column

Limit
Limit will take the first x

Breaking down the Body of a SQL Query
So, in a SQL query you have
- Essential part defines the result and what data you are pulling from,
- Optional part allows you to change the data by filtering, aggregating, sorting or limiting your result

1. Select- Everything after the *select* keyword represents the output of your query. It’s the result.
2. From- The data you’re manipulating. It can be a table or the result of another query, usually called *sub-query* or *inner query*.
3. Where- Used to filter the data and to specify the set of conditions the data needs to comply to, for you to produce an output.
4. Group by- Indicates you’re aggregating the data, e.g., counting, or summing values.
5. Order by- How you want to sort the results.
6. Limit- Indicates you only want to display a certain number of results
